How small do my tasks need to be (aka how fast is IPython)?
In parallel computing, an important relationship to keep in mind is the ratio of computation to communication. In order for your simulation to perform reasonably, you must keep this ratio high. When testing out a new tool like IPython, it is important to examine the limit of granularity that is appropriate. If it takes half a second of overhead to run each task, then breaking your work up into millisecond chunks isn’t going to make sense.
Sending and receiving tiny messages gives us a sense of the minimum time IPython must spend building and sending messages around. This should give us a sense of the minimum overhead of the communication system.
These tests were done on the loopback interface on a fast 8-core machine with 4 engines. They should give us a sense of the lower limit on available granularity.
def test_latency(v, n):
tic = time.time()
echo = lambda x: x
tic = time.time()
for i in xrange(n):
v.apply_async(echo, '')
toc = time.time()
v.wait()
tac = time.time()
sent = toc-tic
roundtrip = tac-tic
return sent, roundtrip
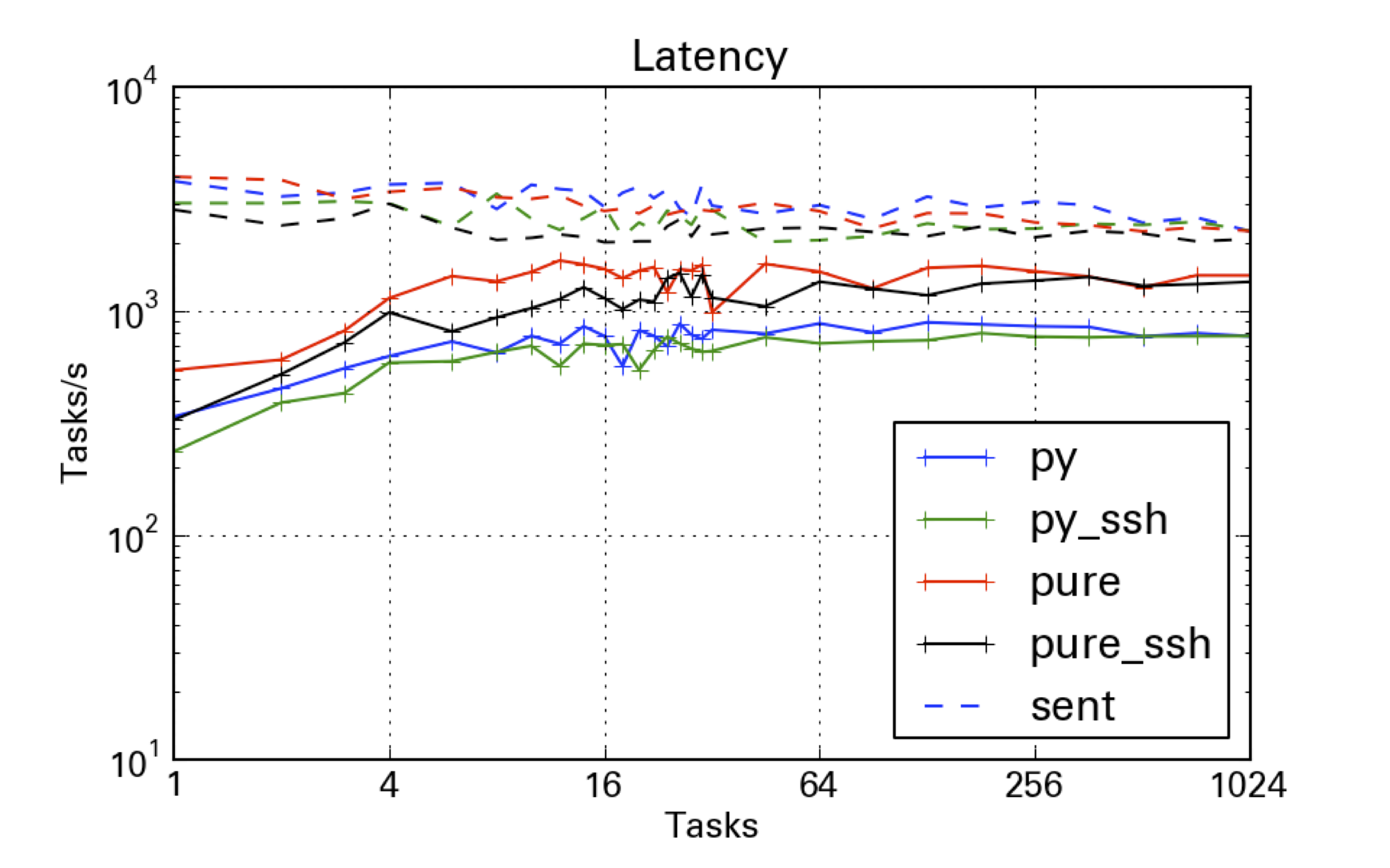
The tests were done with the Python scheduler and pure-zmq scheduler, and with/without an SSH tunnel. We can see that the Python scheduler can do about 800 tasks/sec, while the pure-zmq scheduler gets an extra factor of two, at around 1.5k tasks/sec roundtrip. Purely outgoing - the time before the Client code can go on working, is closer to 4k msgs/sec sent. Using an SSH tunnel does not significantly impact performance, as long as you have a few tasks to line up.
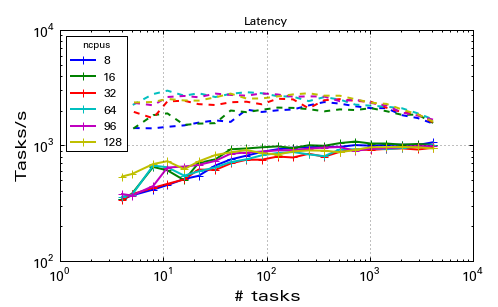
Running the same test on a dedicated cluster with up to 128 CPUs shows that IPython does scale reasonably well.
Echoing numpy arrays is similar to the latency test, but scaling the array size instead of the number of messages tests the limits when there is data to be transferred.
def test_latency(v, n):
A = np.random.random(n/8) # doubles are 8B
tic = time.time()
echo = lambda x: x
tic = time.time()
for i in xrange(n):
v.apply_async(echo, A)
toc = time.time()
v.wait()
tac = time.time()
sent = toc-tic
roundtrip = tac-tic
return sent, roundtrip
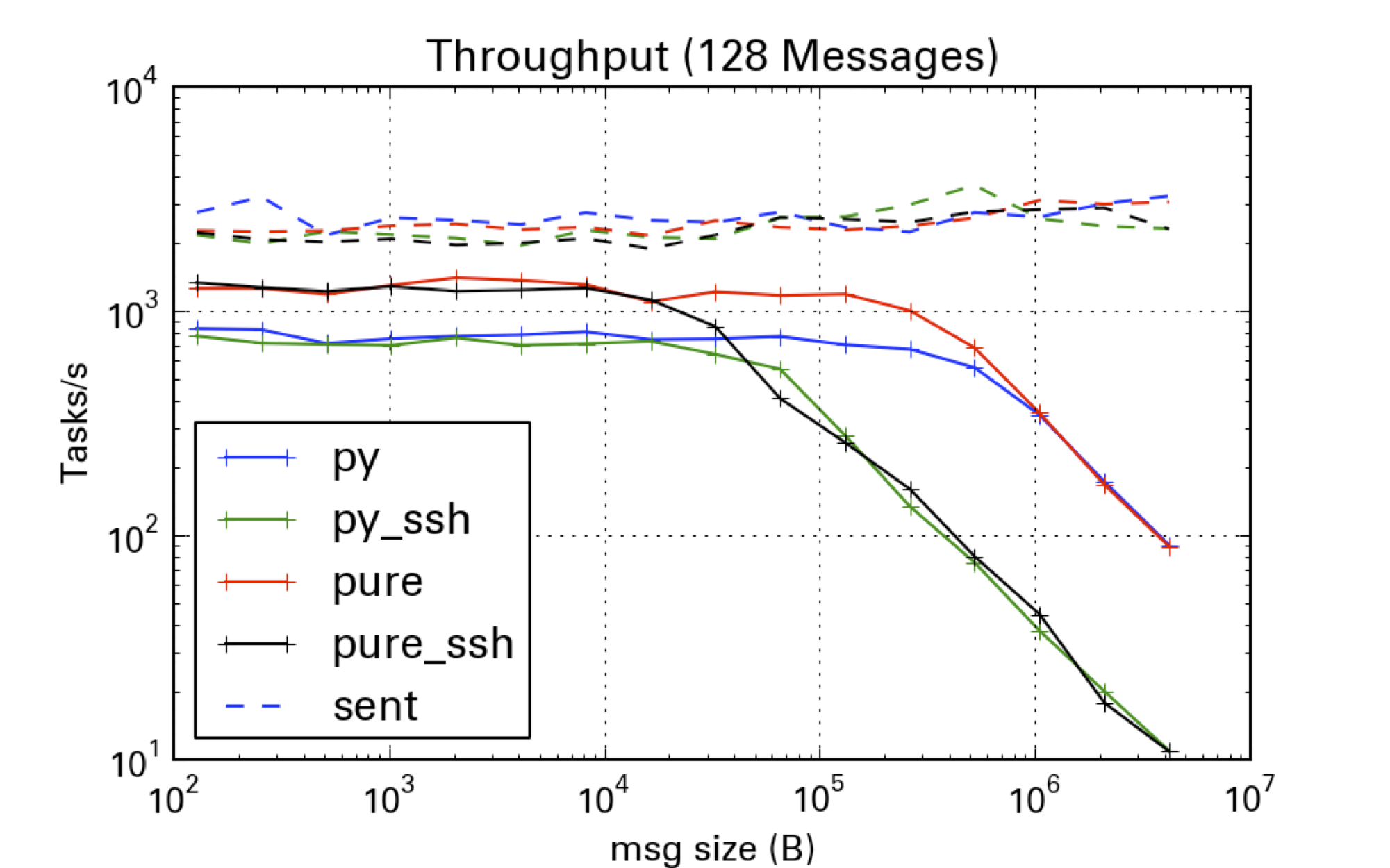
Note that the dotted lines, which measure the time it took to send the arrays is not a function of the message size. This is again thanks to pyzmq’s non-copying sends. Locally, we can send 100 4MB arrays in ~50 ms, and libzmq will take care of actually transmitting the data while we can go on working.
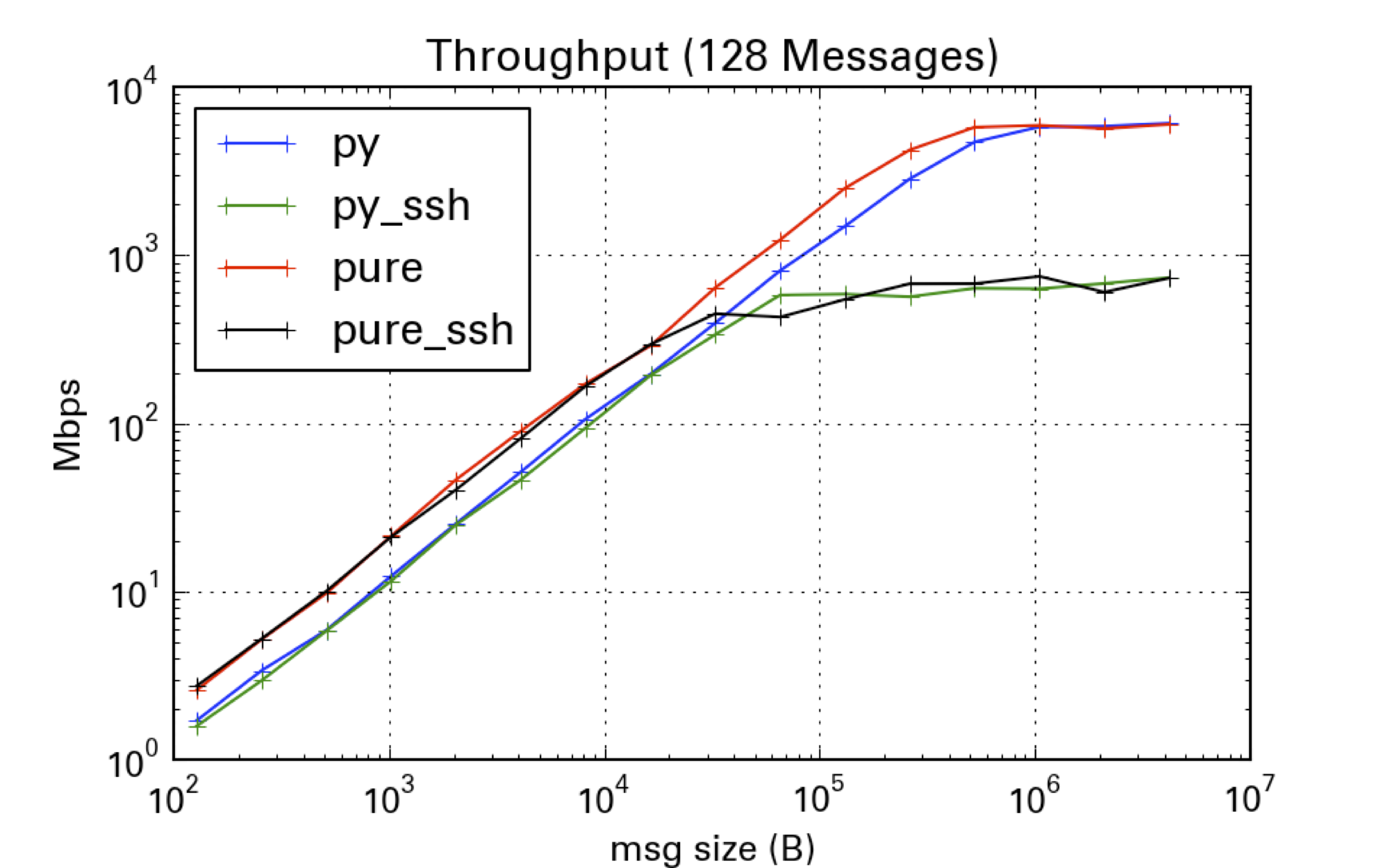
Plotting the same data, scaled by message size shows that we are saturating the connection at ~1Gbps with ~10kB messages when using SSH, and ~10Gbps with ~50kB messages when not using SSH.
Another useful test is seeing how fast view.map() is, for various numbers of tasks and for tasks of varying size.
These tests were done on AWS extra-large instances with the help of StarCluster, so the IO and CPU performance are quite low compared to a physical cluster.
def do_run(v,dt,n):
ts = [dt]*n
tic = time.time()
amr = v.map_async(time.sleep, ts)
toc = time.time()
amr.get()
tac = time.time()
sent = toc-tic
roundtrip = tac-tic
return sent, roundtrip
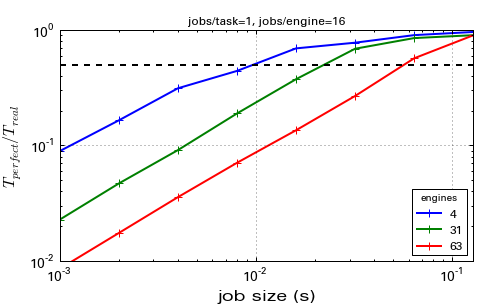
This shows runs for jobs ranging from 1 to 128 ms, on 4,31,and 63 engines. On this system, millisecond jobs are clearly too small, but by the time individual tasks are > 100 ms, IPython overhead is negligible.
Now let’s see how we use it for remote execution.